In order to take advantage of the powerful chips available today, developers must change the way systems are built.

What’s the Big Deal with Concurrent Programming?
Article May 23, 2017
Rob Keefer
As more and more organizations attempt to take advantage of increased data and accessible AI / Machine Learning, traditional approaches to building systems create hidden bottlenecks. A phenomena that we have noticed in our work is that by building concurrent components into our systems we have increased performance by 10 to 100 times. What is going on here?
In 2006 when dual-core processors first became available, the actual performance increase was marginal due to the latency associated with system overhead such as memory swapping, disk drive read and writes, network traffic, etc. The actual performance increase is estimated to be approximately n/ln(n). So, when one core was added, no one really paid attention.
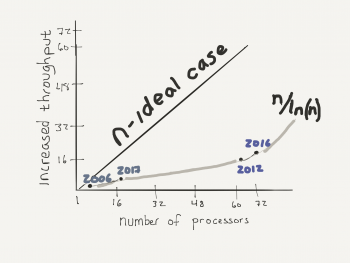
Last year, 10 years after the dual-core processor, Intel in collaboration with Argonne National Labs, released a 72 core processor. A system with 72 cores performs at 16 to 17 times faster than a one core processor. This difference is the same as a car traveling at 55 mph vs one traveling 900 mph. There is no real comparison!
It is not hard to imagine that 10 years from now this processing power will be in our laptops. The operating systems can only account for a portion of the performance increase. Developers now need to be cognizant of their design decisions and how to maximize the power accessible from these processors.
Looking for a guide on your journey?
Ready to explore how human-machine teaming can help to solve your complex problems? Let's talk. We're excited to hear your ideas and see where we can assist.
Let's Talk